Anthropic发布Claude Opus 4.5,综合测评:编程性能全面提升!
2025年11月25日,Anthropic正式发布最新AI模型Claude Opus 4.5,定位为在编码、智能体以及计算机操作方面表现领先的通用模型。在软件工程测试中,该模型的表现超越了所有人类测试者,标志着AI编程能力迈入新阶段。本文将详细介绍Claude Opus 4.5的核心特性及在Cursor中的使用方法。
Claude Opus 4.5核心亮点
根据Anthropic官方介绍,Claude Opus 4.5在多个关键领域实现了突破性进展:
性能表现
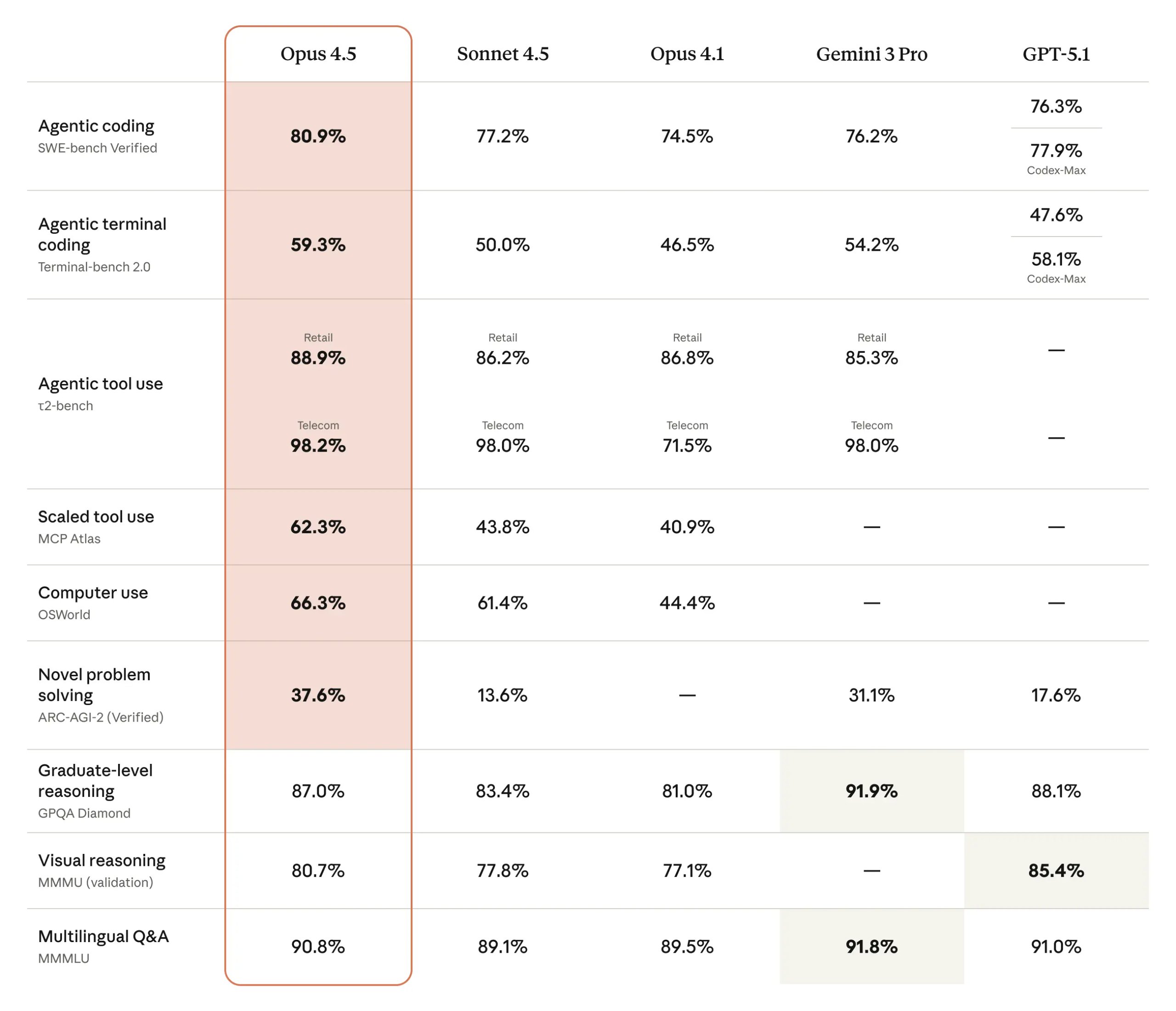
- 超越人类工程师:在Anthropic内部的高难度软件工程测试中,Claude Opus 4.5在规定的2小时限时内得分超过了历来所有人类候选人
- 视觉与推理提升:在视觉、推理与数学方面取得显著进步,多个领域达到行业先进水平
- 深度研究能力:在深度研究、演示文稿处理以及电子表格任务上实现实质性提升
- 智能体协调:在管理子智能体方面表现良好,可用于构建协调性更高的多智能体系统
效率优化
- Token消耗降低:任务执行步骤减少,推理过程中的回溯与冗余更少
- 中等effort设置:与Sonnet 4.5在SWE-bench Verified上达到相近分数,但输出Token使用量减少76%
- 最高effort设置:得分比Sonnet 4.5高出4.3个百分点,同时减少48%的输出Token
- 深度研究提升:结合努力控制、上下文压缩与高级工具使用,性能提升近15个百分点
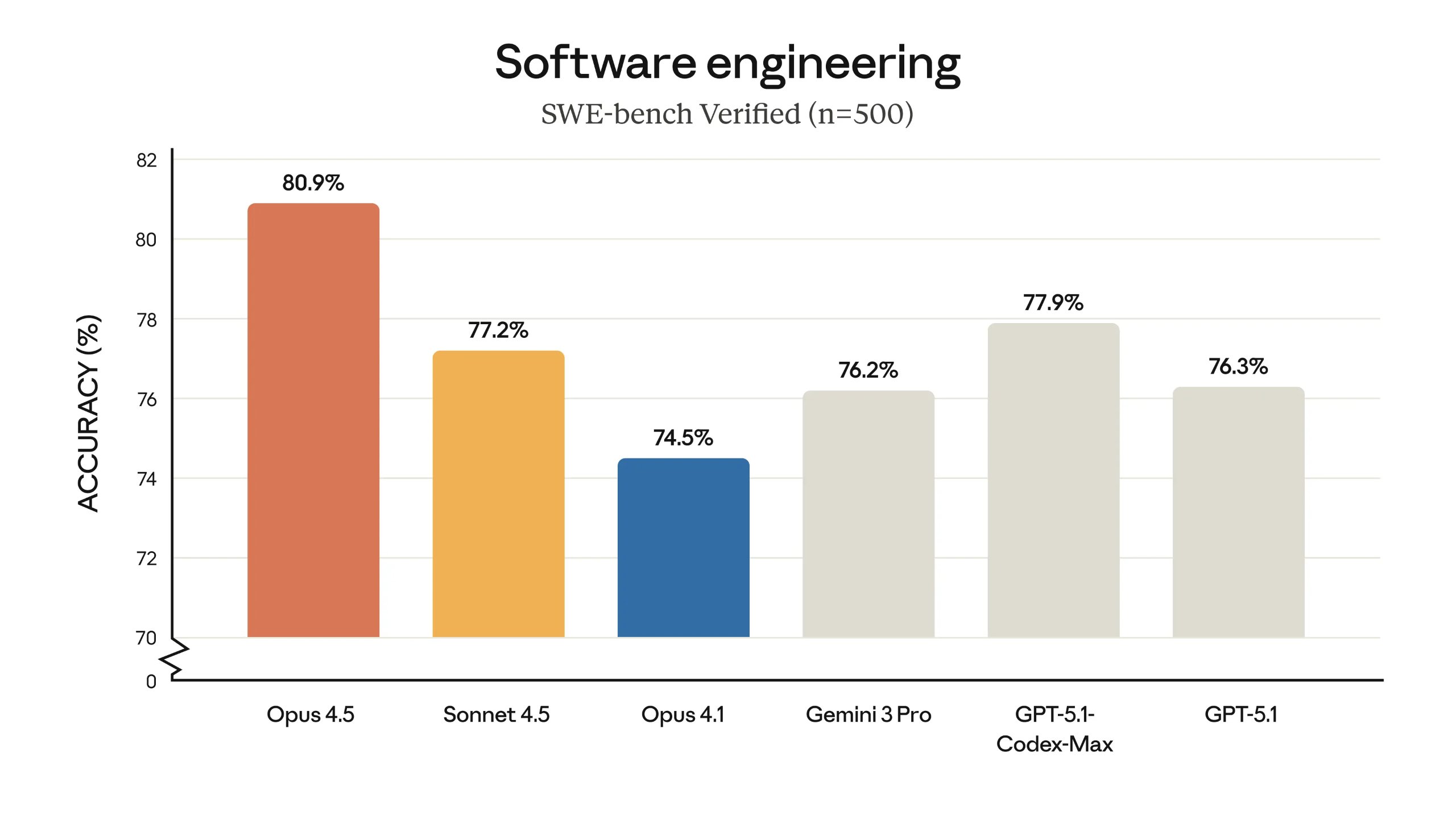
τ2-bench基准测试亮点
在模拟航空公司服务场景的τ2-bench测试中,Claude Opus 4.5展现了创造性解决问题的能力。面对"基础经济舱机票不可修改"的规则,模型提出了"先升级舱位,再变更航班"的替代方案——虽然增加费用,但完全符合航空公司条款,体现了超越预设路径的洞察力。
安全性重大升级
Anthropic表示,Claude Opus 4.5是其迄今对齐程度最高的模型:
- 行业领先对齐:推测其对齐水平在行业前沿模型中处于领先位置
- 提示注入防御:进一步强化对提示注入攻击的防御能力
- 欺骗指令抵御:能更有效避免欺骗性指令的影响
- 奖励规避防范:针对"reward hacking"等潜在风险进行了专门的安全测试
定价与可用性
Claude Opus 4.5已在Anthropic应用、API以及三大云平台开放使用:
- 输入定价:5美元/百万tokens(约合35.6元人民币)
- 输出定价:25美元/百万tokens(约合177.8元人民币)
- API版本:开发者可通过Claude API使用
claude-opus-4-5-20251101版本 - 使用上限:拥有Opus 4.5权限的用户已取消该模型的特定使用上限
开发者平台新功能
effort参数控制
开发者可通过Claude API中新增的effort(投入度)参数,在速度、成本与能力之间进行灵活调节:
- 低effort:快速响应,适合简单任务
- 中等effort:平衡性能与成本,Token消耗显著降低
- 高effort:最佳性能,适合复杂编程任务
Claude Code更新
- Plan Mode增强:现在会先通过提问澄清需求,再生成可编辑的plan.md文件并执行任务
- 桌面应用支持:Claude Code已登陆桌面应用,可同时运行多个本地与远程会话
- 长对话支持:系统会自动总结旧内容以持续展开聊天,不再受长度限制
产品扩展
Claude for Chrome已向所有Max用户开放,Claude for Excel也扩展到Max、Team与Enterprise用户的测试权限。Max与Team Premium用户的总体额度也有所提升。
在Cursor中使用Claude Opus 4.5
模型选择步骤
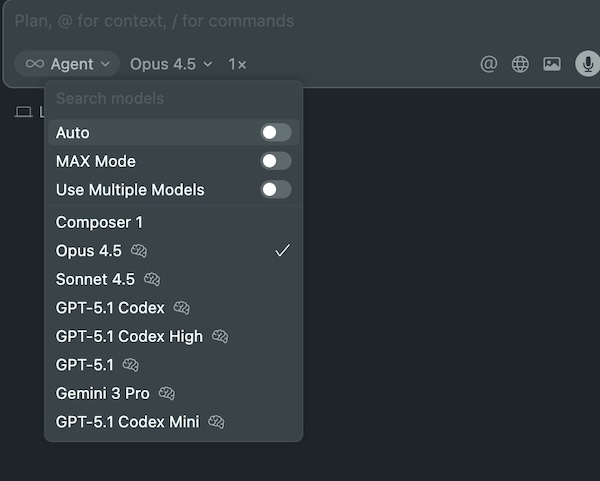
- 打开Cursor编辑器
- 点击右上角的模型选择器
- 在可用模型列表中查找"Claude Opus 4.5"或"claude-opus-4-5"
- 选择该模型开始使用
最佳使用场景
- 复杂编程任务:利用其超越人类的软件工程能力处理高难度开发任务
- 多智能体协作:构建需要协调多个AI代理的复杂系统
- 深度代码研究:分析大型代码库,进行深度重构和优化
- 企业级安全需求:对安全性和对齐程度有高要求的商业项目
与其他模型对比
Claude模型系列定位
- Claude Opus 4.5:旗舰模型,最强综合能力,适合复杂任务
- Claude Sonnet 4.5:平衡性能与成本,SWE-bench得分82%
- Claude Haiku 4.5:轻量快速,适合简单任务和实时应用
行业影响与未来展望
Claude Opus 4.5的发布引发了关于AI将如何改变工程职业的讨论:
- 技术能力边界:在限时测试中超越人类,展示了AI在特定任务上的优势
- 协作模式演变:从"AI辅助编程"向"AI主导+人类审核"模式转变
- 安全研究重点:Anthropic的"社会影响与经济未来"研究团队正关注此类变化
- 工作方式变革:预示着未来工作方式将出现更广泛的变化
使用建议
虽然Claude Opus 4.5在测试中表现出色,但该测试主要考察技术能力与压力下的判断力,并不涉及协作或长期经验等能力。在实际项目中,建议结合人工审查和团队协作,充分发挥AI与人类各自的优势。