ChatGPT 5.2发布:号称智能体编码最强,拳打Gemini 3.0 Pro、脚踢Claude 4.5
OpenAI正式发布GPT-5.2系列模型,这是OpenAI迄今最先进的AI模型。GPT-5.2包含Instant、Thinking和Pro三个版本,其中GPT-5.2 Thinking刷新了SWE编码能力测试历史最高分(80%),也是OpenAI首个性能达到或超过人类专家水平的模型。CEO Sam Altman表示,Gemini 3对OpenAI的影响没之前担心的大,预计明年1月解除"红色警报"。
📑 本文目录
🚀 GPT-5.2概述
GPT-5.2是OpenAI迄今最先进的人工智能模型,针对专业工作场景进行了全面优化,创下多个基准测试的行业记录。OpenAI应用业务CEO Fidji Simo表示,GPT-5.2在以下方面均优于前代产品:
- 创建电子表格 - 更高效的数据处理能力
- 制作演示文稿 - 智能内容生成与布局
- 图像识别 - 被称为"世界上最好的视觉模型"
- 代码编写 - SWE编码测试创历史新高
- 长文本理解 - 25.6万token范围内实现近100%准确率
GPT-5.2已在ChatGPT上线,面向Plus、Pro、Go、Business和Enterprise付费套餐用户,API同步开放给所有开发者。付费用户在未来三个月内仍可继续使用GPT-5.1。
📦 GPT-5.2三个版本详解
GPT-5.2 Instant - 快速高效的日常助手
Instant是快速高效的日常工作和学习助手,延续了GPT-5.1 Instant中更亲切的对话风格。早期测试者注意到,GPT-5.2的解释更加清晰,能够直接呈现关键信息。
- 信息查询显著提升
- 操作指南更加清晰
- 技术写作质量提高
- 翻译能力增强
GPT-5.2 Thinking - 深度工作的最佳选择
Thinking专为深度工作而设计,能够帮助用户更高效地完成复杂任务。这是OpenAI首个性能达到或超过人类专家水平的模型,也是当前"世界上最好的视觉模型"。
- 编码能力 - SWE-bench Verified达到80%新高
- 长文档总结 - 25.6万token范围内近100%准确率
- 文件问答 - 深度理解上传文件内容
- 数学逻辑 - 逐步进行推理运算
- 规划决策 - 更清晰的框架和有用细节
GPT-5.2 Pro - 最智能可靠的选择
Pro是需要高质量回答难题时"最智能、最可靠"的选择,也是"世界上最好的科学家助手模型"。早期测试表明,它在编程等复杂领域表现更出色,且重大错误更少。
| 版本 | 定位 | 最佳场景 |
|---|---|---|
| Instant | 快速高效 | 日常查询、简单任务、快速回答 |
| Thinking | 深度思考 | 复杂编码、长文档、数学推理 |
| Pro | 最智能可靠 | 科学研究、高难度问题、专业任务 |
📊 性能与基准测试
GPT-5.2在多个关键基准测试中刷新了行业纪录,充分展示了其强大的综合能力。
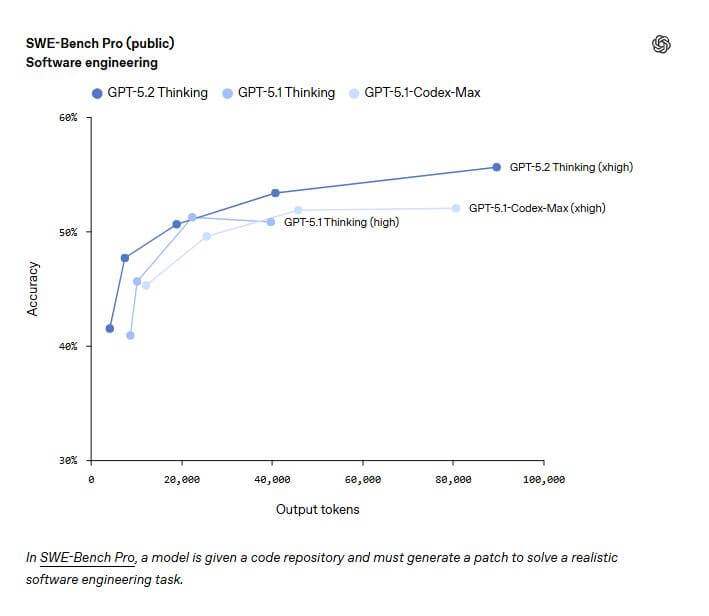
🏆 编码能力
| 测试项目 | GPT-5.2 Thinking | 说明 |
|---|---|---|
| SWE-Bench Pro | 55.6% | 真实世界软件工程任务 |
| SWE-bench Verified | 80% 🏆 | 历史最高分,涵盖四种编程语言 |
OpenAI的产品负责人Max Schwarzer表示,GPT-5.2在代码生成和调试方面取得重大进步。Windsurf和CharlieCode等编码初创公司报告称,该模型实现了"最先进的智能体编码性能"。
🧠 知识工作能力
在GDPval测试中,GPT-5.2在涵盖44个职业的知识工作任务上表现出色:
- 70.9%的表现达到或超过行业专家水平
- 完成任务速度是专家的11倍以上
- 成本不到专家的1%
🔬 科学研究能力
| 测试项目 | GPT-5.2 Pro | GPT-5.2 Thinking |
|---|---|---|
| GPQA Diamond(科学问答) | 93.2% | 92.4% |
| FrontierMath(专家级数学) | - | 40.3% 🏆 |
👁️ 视觉能力
OpenAI声称GPT-5.2 Thinking是"世界上最好的视觉模型":
- 图表推理错误率降低约50%
- 软件界面理解错误率降低约50%
💰 定价与使用
GPT-5.2在API平台的定价如下:
| 项目 | 价格 | 说明 |
|---|---|---|
| 输入Token | $1.75/百万 | 缓存输入可享90%折扣 |
| 输出Token | $14/百万 | - |
虽然单token价格高于GPT-5.1,但OpenAI表示,由于模型效率更高,达到相同质量水平的总成本反而更低。目前没有弃用GPT-5.1、GPT-5或GPT-4.1的计划。
如果你正在使用Cursor等AI编程工具,可以参考Cursor使用GPT-5指南来使用GPT-5.2模型。
⚔️ 与Gemini 3的竞争
GPT-5.2的发布是OpenAI对Gemini 3掀起新一轮竞争的正式回应。几周前,谷歌推出的Gemini 3因其推理和编码能力广受好评,迅速登上LMArena和Humanity's Last Exam等权威排行榜榜首,给OpenAI带来压力。
本周稍早媒体报道,OpenAI CEO Sam Altman最近发布内部"红色警报"备忘录,要求公司将资源集中用于改进ChatGPT。OpenAI应用业务CEO Simo解释称,红色警报是为了"向公司发出信号,表明我们希望将资源集中在某个特定领域"。
面对竞争压力,Altman在采访中表示:
"Gemini 3对我们指标的影响可能没有我们担心的大。"
Altman预计OpenAI将在2025年1月前以"非常强势的地位"退出红色警报模式。
🏢 企业级应用
GPT-5.2的发布明确瞄准企业市场。OpenAI数据显示,过去一年其AI工具的企业使用量大幅飙升:
- ChatGPT Enterprise平均用户表示AI每天为他们节省40至60分钟
- 重度用户每周节省超过10小时
企业客户反馈
| 客户类型 | 代表企业 | 反馈 |
|---|---|---|
| 通用企业 | Notion、Box、Shopify、Zoom | 最先进的长周期推理和工具调用性能 |
| 数据科学 | Databricks、Hex、Triple Whale | 智能体数据科学和文档分析任务出色 |
| 编码工具 | Cognition、Warp、JetBrains | 最先进的智能体编码性能 |
工具调用能力
在工具调用方面,GPT-5.2 Thinking在Tau2-bench Telecom测试中达到98.7%的准确率,展示了其在长时间、多轮次任务中可靠使用工具的能力。
在一个涉及航班延误、转机失败和医疗座位需求的复杂客户服务案例中,GPT-5.2成功协调了重新预订、特殊协助座位和补偿等全部流程。
📝 总结
GPT-5.2是OpenAI迎战Gemini 3的重磅回应,在多个关键领域取得突破性进展:
| 领域 | 亮点成绩 |
|---|---|
| 编码能力 | SWE-bench Verified 80%(历史最高) |
| 专家水平 | 首个达到/超过人类专家水平的AI模型 |
| 效率提升 | 速度是专家11倍,成本不到1% |
| 视觉理解 | "世界上最好的视觉模型" |
| 长文本 | 25.6万token范围内近100%准确率 |
评论认为,GPT-5.2与其说是重新发明,不如说是对OpenAI最近两次升级(GPT-5和GPT-5.1)的整合和强化,使其成为生产应用更可靠的基础。随着AI竞争日益激烈,开发者可以期待更多创新和价格优化。