Gemini 3发布:能力概览、Claude对比与免费体验教程
Google在2025年11月正式推出Gemini 3系列,定位“史上最智能的多模态大模型”,并同步上线Antigravity编码平台、搜索与Workspace等盈利产品。本文快速梳理Gemini 3的三大亮点:更强推理、多工具Agentic编码、可落地的免费体验路径,并提供与Claude系列的对比分析。
一、Gemini 3 核心能力速览
Google于2025年11月推出的Gemini 3系列,在推理、编码与多模态能力上实现了显著升级:
- 百万级上下文:支持100万token输入与64K输出,适合长文档分析与知识库问答。
- 推理与数学:AIME 2025测试中,开启代码执行后达到100%准确率,逻辑推理能力大幅提升。
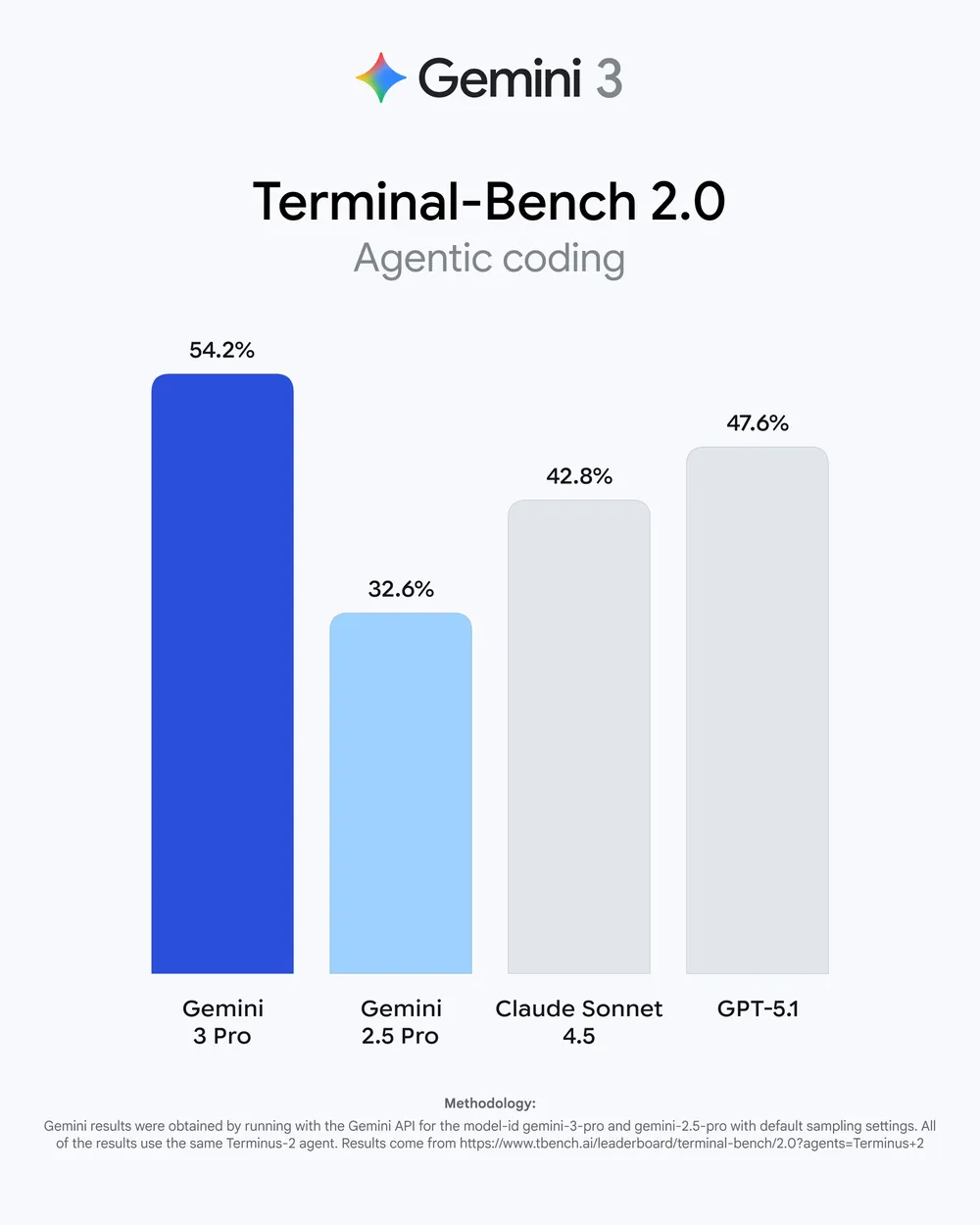
- Agentic Coding:LiveCodeBench Pro得分2439,逼近专业竞赛级水平;Terminal-Bench 2.0得分54.2%,胜任复杂终端任务。
- Antigravity平台:允许AI在编辑器、终端、浏览器间自主切换,实现"需求→代码→部署"的全流程接管。
Gemini 3 + Antigravity能做什么?
Antigravity允许团队把需求直接交给自主代理,由AI在编辑器、终端、浏览器之间完成"理解需求 → 写代码 → 运行测试 → 部署验证"的全流程,这种"AI主导开发"路线为多Agent IDE(包括 Cursor)提供了新的竞品压力。
二、实用功能亮点
根据社区实践,Gemini 3在以下场景展现出"真正能落地"的能力:
2.1 极速代码生成
实测不到3分钟可生成1600+行完整代码。例如:
- 物理模拟:准确理解物理需求,生成零错误的小球碰撞模拟程序。
- 全栈应用:生成包含前端交互与数据加载的无限滚动短视频应用。
- Bug修复:彻底解决困扰AI编程的"渐变紫"显示问题。
2.2 视觉与文档理解
- 手写识别:精准提取潦草中文手写稿,18世纪文稿OCR错误率仅0.56%。
- 图像推理:不仅识别内容,还能进行深度逻辑分析。
2.3 自动化与长任务
- 竞赛级编程:LiveCodeBench Pro得分接近ICPC难度。
- DevOps自动化:Terminal-Bench 2.0表现领先,适合自动化脚本编写。
- 长任务规划:Vending-Bench 2得分大幅领先,胜任跨工具协同任务。
三、Gemini 3 与 Claude 系列对比
| 指标 | Gemini 3 Pro | Claude 4.5 / 3.7 | 差异点 |
|---|---|---|---|
| LiveCodeBench | 2439 | ~1420 | Gemini在复杂算法题更强 |
| SWE-bench | 76.2% | 77.2% | Claude在Git补丁任务略稳 |
| 数学推理 | 100% (Code Exec) | ~94% | Gemini工具链结合更优 |
| 终端自动化 | 54.2% | 42.8% | Gemini更适合DevOps场景 |
选择建议
关注多模态推理、自动化执行、长任务选Gemini 3;依赖稳定补丁、文档编写选Claude。两者在不同场景各有优势。
四、典型应用场景
- 企业知识检索:利用百万token处理大型合同与文档。
- 工程流水线:借助Agent在编辑器/终端间循环执行任务。
- 多模态创作:统一处理图文视频,生成营销素材。
- 科研推导:通过代码执行获得可复现的推理过程。
五、免费体验教程
国内用户可通过以下方式体验:
- DeepSider扩展(推荐):安装浏览器侧边栏插件,直接调用Gemini 3完成代码生成与文档解析。
- LMArena沙箱:在官方竞技平台体验长上下文对话与图像分析。
- Google AI Studio:注册Google Cloud领取试用额度,接入API或申请Antigravity预览。
- VS Code集成:配合DeepSider等工具,将生成代码同步至本地项目。
使用提示
使用第三方工具时,请注意模型调用额度与数据隐私,避免上传敏感代码。
常见问题
- 何时全面开放? 模型已上线部分产品,Antigravity需申请预览。
- 能否本地部署? 暂无本地版本,需依赖云端API。
- 中文支持? 实测中文手写识别准确,适合中文团队。