DeepSeek V3.2上下文长度限制详解:128K Tokens与最佳实践
DeepSeek V3.2作为最新发布的开源模型,将上下文长度提升至128K tokens(约24万汉字),是影响AI编程体验的核心指标。本文将从实用角度出发,详解DeepSeek V3.2的上下文容量、Token计算方法,以及在Cursor中高效利用上下文的最佳实践。
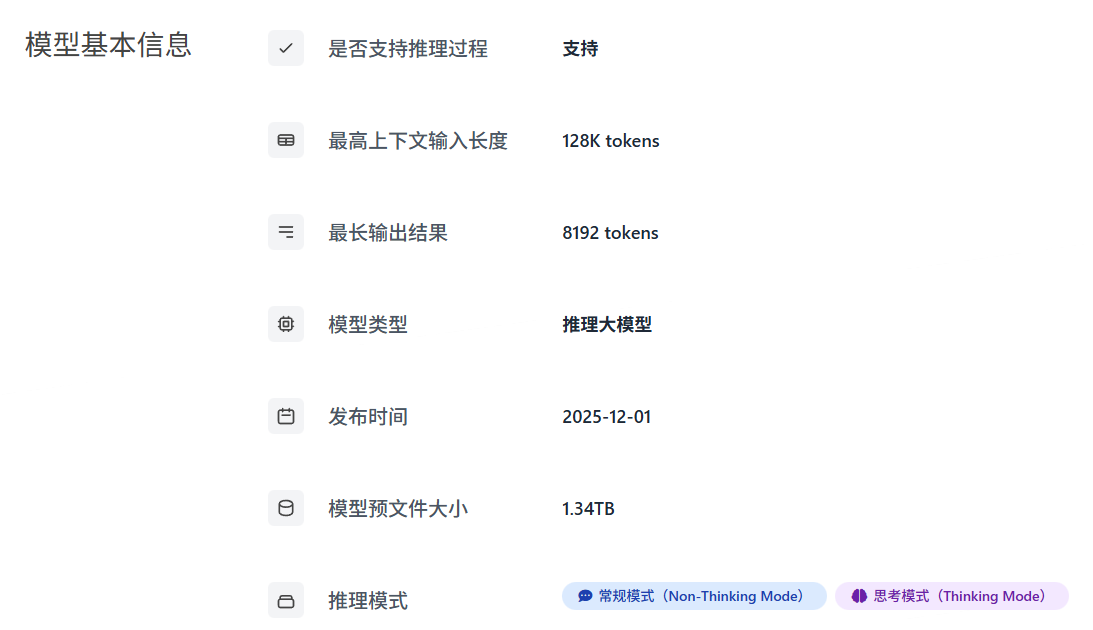
什么是上下文长度与Token?
Token基础概念
Token是AI模型处理文本的基本单位,可以理解为"词元"。不同语言的Token切分规则不同:
- 英文:平均1个单词 ≈ 1.3个Token(如 "programming" = 1 Token)
- 中文:平均1个汉字 ≈ 0.5-0.7个Token(如 "编程" = 1 Token)
- 代码:变量名、符号等各占不同Token数量
上下文长度的重要性
上下文长度决定了模型能"记住"多少内容,包括:
- 您发送的所有消息(Prompt)
- 模型的所有回复(Response)
- 通过
@符号引用的代码文件 - 系统指令和规则设定
128K tokens ≈ 20-24万汉字 ≈ 50万英文单词 ≈ 一本长篇小说的篇幅
DeepSeek各版本上下文长度对比
DeepSeek在不同版本和部署平台上提供了不同的上下文容量:
| 模型/平台 | 上下文长度 | 约等于 | 适用场景 |
|---|---|---|---|
| DeepSeek-V3.1 | 64K tokens | ~10万汉字 | 日常对话、代码补全 |
| DeepSeek-V3.2 | 128K tokens | ~24万汉字 | 长文档分析、项目理解 |
| DeepSeek-V3.2-Exp | 128K tokens | ~24万汉字 | 实验性功能测试 |
| 华为云部署版 | 160K tokens | ~30万汉字 | 超长文本处理 |
DeepSeek V3.2的智能上下文管理
DeepSeek V3.2在模型层面引入了智能上下文管理策略,让128K窗口承载更复杂的长任务。关于V3.2的完整技术架构,可参考DeepSeek V3.2发布:核心技术与Agent革命性突破。
智能体场景下的Token优化
在复杂的"思考+工具调用"场景中,冗长的思维链(Chain of Thought)会迅速消耗Token。V3.2为此设计了特殊的管理机制:
- 丢弃历史思考:当用户输入新消息时,模型会丢弃上一轮的"思考过程",只保留最终结果
- 保留工具记忆:完整保留"工具调用"的历史记录及其返回结果
- 实际效果:避免每次调用工具都重复阅读旧的推理过程,节省Token的同时保证工具状态记忆
应对超长任务的动态压缩策略
针对搜索等极易超出128K限制的任务(如BrowseComp测试中约20%的案例会超限),V3.2引入了测试时动态调整策略:
当Token使用量超过上下文窗口的80%时,系统会自动采取以下策略之一:
- Discard-all策略:丢弃所有之前的工具历史,重置上下文,从头开始
- Summary策略:对历史轨迹进行智能摘要,压缩保留关键信息后继续任务
DeepSeek V3.2不仅提供128K的物理上下文窗口,更通过DSA架构(硬件层面提效)和智能丢弃策略(逻辑层面省流),让这128K在实际应用中能承载更复杂的长任务。
实际应用中的Token消耗估算
了解常见场景的Token消耗,有助于更好地规划上下文使用:
代码文件分析
| 代码规模 | 预估Token | 占128K比例 |
|---|---|---|
| 100行代码 | ~500-800 tokens | ~0.5% |
| 500行代码 | ~2,500-4,000 tokens | ~2-3% |
| 1000行代码 | ~5,000-8,000 tokens | ~5-6% |
| 整个中型项目(50个文件) | ~50,000-80,000 tokens | ~40-60% |
文档处理
| 文档类型 | 预估Token | 是否可一次处理 |
|---|---|---|
| 技术博客(3000字) | ~2,000 tokens | ✅ 轻松处理 |
| API文档(2万字) | ~15,000 tokens | ✅ 可以处理 |
| 技术书籍一章(5万字) | ~35,000 tokens | ✅ 可以处理 |
| 完整技术书籍(30万字) | ~200,000 tokens | ❌ 需要分段 |
多轮对话累积
对话中的Token会不断累积,包括您的问题和AI的回复:
- 简短问答(10轮):约 5,000-10,000 tokens
- 深度讨论(20轮):约 20,000-40,000 tokens
- 复杂项目对话(50轮):可能超过 80,000 tokens
当上下文接近限制时,模型可能会"遗忘"早期对话内容,导致回复质量下降或出现重复建议。
在Cursor中优化DeepSeek上下文使用
1. 使用 @codebase 智能索引
Cursor的 @codebase 功能可以智能检索相关代码,而非加载整个项目:
// 在Chat中使用
@codebase 这个项目的用户认证逻辑是怎么实现的?
// Cursor会智能检索相关文件,而非加载所有代码2. 配置 .cursorignore 排除无关文件
在项目根目录创建 .cursorignore 文件,排除不需要AI理解的内容:
# .cursorignore 示例
node_modules/
dist/
build/
*.log
*.lock
.git/
coverage/
__pycache__/3. 精准引用文件
使用 @文件名 精准引用需要的文件,避免全局搜索:
// 推荐:精准引用
@src/utils/auth.ts 请帮我优化这个认证函数
// 避免:模糊描述
帮我看看项目里的认证代码(会触发大范围搜索)4. 定期开启新对话
当对话变得冗长时,建议:
- 完成一个任务后开启新对话
- 将重要结论总结后带入新对话
- 使用 Memory Bank 保持项目记忆
突破上下文限制的实用技巧
摘要提取法
处理超长文档时,先让AI生成摘要:
第一步:请阅读这份API文档,提取核心要点和关键接口列表
第二步:基于摘要,深入讨论具体实现细节分段处理法
将大型任务拆分为多个独立对话:
- 对话1:分析项目结构和架构
- 对话2:实现用户模块
- 对话3:实现订单模块
- 对话4:集成测试和优化
重要信息前置
在长对话中,将关键需求放在消息开头:
// 推荐格式
【核心需求】实现一个支持分页的用户列表API
【技术栈】Node.js + Express + MongoDB
【具体要求】
1. 支持按用户名搜索
2. 每页20条记录
3. 返回总数用于前端分页与主流模型上下文长度对比
了解不同模型的上下文容量,有助于选择合适的工具:
| 模型 | 上下文长度 | 特点 |
|---|---|---|
| GPT-4o | 128K tokens | 多模态,响应快 |
| Claude 3.5 Sonnet | 200K tokens | 长文本处理优秀 |
| Claude Opus 4.5 | 200K tokens | 编程能力顶尖 |
| Gemini 3 Pro | 2M tokens | 超长上下文王者 |
| DeepSeek-V3.2 | 128K tokens | 开源、性价比高 |
常见问题解答
Q1:超出上下文限制会发生什么?
A:当对话超出上下文限制时,模型会自动"截断"早期内容。这意味着:
- 早期的对话内容会被"遗忘"
- 可能出现重复建议或前后矛盾
- 复杂任务的连贯性会受影响
Q2:DeepSeek的128K上下文够用吗?
A:对于大多数开发场景,128K tokens已经非常充足:
- 可以分析整个中型项目的代码结构
- 可以处理完整的技术文档
- 可以进行20-30轮深度技术讨论
总结
DeepSeek V3.2提供的128K tokens上下文长度,能够满足绝大多数开发场景的需求。通过合理使用Cursor的智能索引功能、配置忽略文件、以及采用摘要和分段策略,您可以充分发挥这一上下文容量的潜力,获得更流畅的AI辅助编程体验。
- 128K tokens ≈ 24万汉字,足够分析中型项目
- 使用 @codebase 和 .cursorignore 优化Token使用
- 长对话时采用分段处理和摘要提取策略
- 定期开启新对话,保持AI响应质量