开源新王炸!DeepSeek V3.2 发布:推理比肩GPT-5,Agent能力迎来革命性突破
12月1日,DeepSeek正式发布了其V3.2系列大模型,为全球开源AI社区带来了一次里程碑式的更新。此次发布不仅是技术的常规迭代,更是一次性能上的巨大飞跃,其表现直接挑战了业界顶级的闭源模型。DeepSeek V3.2的到来不仅是一次更新,更是一份宣言:开源阵营不再只是追赶,而是开始在人工智能的核心创新领域中定义节奏。
1. 引言:AI格局迎来新变量
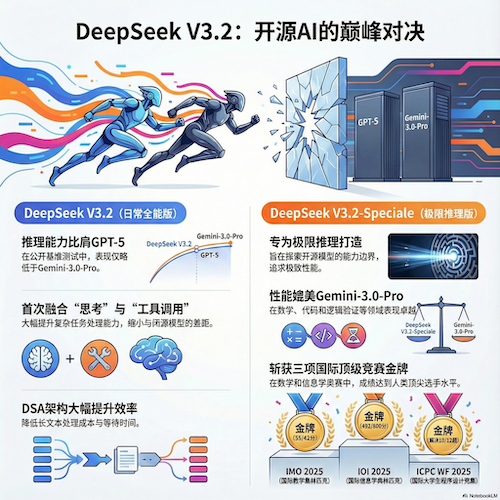
本次发布的重大意义,在于其并非简单的参数堆砌或数据增量,而是在模型架构、Agent(智能体)能力以及训练方法论上实现了根本性的创新。这使得新模型在推理能力上达到了与GPT-5比肩的水平,同时在处理复杂任务的智能体能力上取得了革命性突破。
本文将深入剖析DeepSeek V3.2系列推出的两款重磅模型,解析其背后驱动性能飞跃的核心技术,并探讨这一开源领域的重大进展对人工智能未来发展的深远影响。
2. 双剑齐发:详解DeepSeek V3.2系列两大模型
DeepSeek此次采取了"双剑齐发"的战略,同时发布两款定位清晰、各有所长的模型。这一策略精准地满足了市场的多样化需求,既为用户的日常工作提供了兼具效率与性能的强大工具,也为探索AI能力极限的研究者提供了前所未有的开源利器。与此前发布的Claude Opus 4.5和Google Gemini 3形成了三足鼎立的竞争格局。
| 模型 (Model) | 核心定位与关键成就 |
|---|---|
| DeepSeek-V3.2 | 平衡推理与效率,面向日常应用。专为问答、通用Agent任务等日常场景设计,实现了推理能力与输出效率的最佳平衡。其性能达到了GPT-5的水平,且仅略低于Gemini-3.0-Pro,同时相比Kimi-K2-Thinking等竞品,大幅降低了输出长度和计算成本。 |
| DeepSeek-V3.2-Speciale | 挑战推理极限,探索能力边界。作为长思考增强版,该模型旨在将开源模型的推理能力推向极致,性能表现媲美Gemini-3.0-Pro。它集成了DeepSeek-Math-V2的定理证明能力,具备顶级的指令跟随、数学证明和逻辑验证能力。 |
Speciale版本:奥赛金牌的含金量
DeepSeek-V3.2-Speciale的发布,是开源模型首次在如此广泛的顶级竞赛中取得的突破性成就,其斩获的一系列金牌充分证明了其卓越的推理实力:
- 国际数学奥林匹克 (IMO) 2025: 金牌
- 中国数学奥林匹克 (CMO) 2025: 金牌
- 国际大学生程序设计竞赛全球总决赛 (ICPC World Finals) 2025: 金牌,其实力达到了与人类竞赛亚军团队相当的水平
- 国际信息学奥林匹克 (IOI) 2025: 金牌,其实力达到了与人类竞赛全球第十名选手相当的水平
那么,究竟是怎样的技术突破,支撑了如此巨大的性能飞跃?
3. 揭秘底层创新:驱动性能飞跃的两大核心技术
DeepSeek V3.2系列的惊艳表现并非偶然,而是源于底层架构和核心机制的精准创新。本节将深入剖析其背后的两大关键技术:全新的稀疏注意力机制,以及彻底改变AI与工具交互方式的智能体新范式。
3.1 DeepSeek Sparse Attention (DSA):重塑效率与成本
传统注意力机制在处理长序列时面临着一个核心瓶颈:其计算复杂度会随着序列长度(L)的平方(O(L²))增长,这极大地限制了模型的效率和可扩展性。
DSA核心创新
DeepSeek引入了DeepSeek Sparse Attention (DSA) 稀疏注意力机制。DSA通过两大核心组件——"闪电索引器"(lightning indexer)和"细粒度Token选择"(fine-grained token selection)机制,巧妙地将计算复杂度从O(L²)降低至O(Lk),其中k远小于L。
这一架构创新在不牺牲模型性能的前提下,显著提升了长序列处理的效率,并大幅降低了推理成本。此前在V3.2-Exp实验版上进行的大量用户测试已经充分验证了DSA的有效性。这不仅是一项学术层面的优化,更是复杂、长周期Agent任务和海量文档处理的根本性赋能技术,使得这类应用在成本上真正变得可行。如果您正在使用自定义API密钥,可以考虑接入DeepSeek的API服务。
3.2 "思考融入工具调用":AI Agent的革命性进化
DeepSeek V3.2是该公司推出的首个将"思考"(thinking)过程与工具使用深度融合的模型。这标志着AI Agent的能力实现了一次革命性的进化。
以往的模型大多采用"直接调用工具"的简单模式,接到指令后立即执行工具,缺乏规划和验证环节。而DeepSeek V3.2引入了一种更接近人类解决问题方式的"思考-行动-反思"闭环。
- 模型在调用工具前会先进行分析和规划
- 执行后还会对结果进行验证和修正
- 这种机制使得模型在处理搜索、编程、项目规划等需要多步骤推理和执行的复杂任务时,能力获得了指数级的提升
思考上下文管理机制
DeepSeek V3.2创新的思考上下文管理机制,仅在新用户消息出现时才丢弃历史推理内容。这一设计避免了在多步工具调用中重复进行不必要的推理,从而大幅提升了复杂Agent任务的效率与连贯性。
但即使是最先进的架构也需要正确的"燃料"来学习,这正是DeepSeek全新训练策略发挥作用的地方。
4. 成功的秘诀:彻底升级的训练策略
一个模型的最终能力是在训练阶段被锻造出来的。DeepSeek V3.2的强大实力,源于其在训练数据生成和强化学习(RL)规模化方面的革命性方法。
4.1 大规模Agent任务合成:用"极限题库"锤炼模型
DeepSeek搭建了一条全新的大规模Agent训练数据合成流水线。通过该流水线,团队构造了超过 1800个环境 和 85000多条复杂指令,用于模型的强化学习。
- 任务被设计为"难解答,易验证"的模式
- 摆脱了对昂贵且稀缺的人类标注数据的依赖
- 通过让模型在这些精心构造的"极限题库"中进行锤炼,其解决复杂问题的泛化能力被推向了新的高度
4.2 可扩展的强化学习:用巨量算力"换"能力
DeepSeek在模型的后训练(post-training)阶段进行了史无前例的巨大投入,其后训练的计算预算已超过预训练成本的10%。团队采用了GRPO (Group Relative Policy Optimization) 算法,并在此基础上引入多项稳定性改进,构建了一套稳定、可扩展的强化学习框架。
研究员观点
这一理念在DeepSeek研究员苟志斌的阐述中得到了最好的体现:当竞争对手还在证明扩大预训练规模的价值时,DeepSeek的工作则证明了规模化强化学习同样是通往更强能力的康庄大道。他精辟地指出:"后训练的瓶颈,是靠优化方法和数据而不是靠等待一个更强的基础模型来解决的。"
正是这种先进架构效率与革命性数据策略的结合,让DeepSeek V3.2成为了真正的游戏规则改变者。
5. 这意味着什么:开源AI的新纪元已经到来
从技术细节回归产业全局,DeepSeek V3.2的发布不仅仅是一款新模型的问世,它更是一个明确的信号:人工智能行业的权力结构正在发生深刻变化。
- 打破技术垄断: 此次发布雄辩地证明,顶级性能的大模型不再是少数闭源巨头的专属领域。通过正确的技术路线和战略投入,开源模型已经具备了与第一梯队正面竞争的实力。
- 赋能开发者与企业: 对开发者而言,一个成本更低、可定制性更强、性能更卓越的基座模型已经触手可及。对企业而言,这意味着构建强大的AI系统不再需要完全依赖海外的API接口,为技术自主和应用创新提供了坚实的基础。
- 重塑产业竞争: 人工智能领域的军备竞赛正在迅速演化。新的竞争前沿不再是原始的参数数量比拼,而是由三大支柱构成的能力三角:架构效率(如DSA)、创新的数据合成流水线,以及对大规模强化学习的战略性投入。DeepSeek刚刚在这三个维度上同时证明了自己的顶尖实力,重绘了行业竞争的优势版图。
如果您对这些激动人心的可能性感到兴奋,不妨亲手体验一下这些模型的力量。
6. 立刻上手:拥抱开源新力量
我们鼓励广大开发者、研究人员和AI爱好者立即探索DeepSeek V3.2系列模型,共同见证并参与到这场开源AI的变革中。您可以通过Cursor的模型配置来使用这些强大的开源模型。
以下是模型的官方开源地址:
DeepSeek-V3.2
- HuggingFace: huggingface.co/deepseek-ai/DeepSeek-V3.2
- ModelScope: modelscope.cn/models/deepseek-ai/DeepSeek-V3.2
DeepSeek-V3.2-Speciale
- HuggingFace: huggingface.co/deepseek-ai/DeepSeek-V3.2-Speciale
- ModelScope: modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Speciale
开源AI新纪元
DeepSeek V3.2的发布,为我们揭示了协同合作、开放共享的AI发展模式所蕴含的无限潜力。一个由开源力量驱动的AI新纪元,已经到来。